
001: JavaScript内存机制之问——数据是如何存储的?
一言以蔽之: 基本数据类型用栈存储,引用数据类型用堆存储。
具体而言,以下数据类型存储在栈中:
- boolean
- null
- undefined
- number
- string
- symbol
- bigint
而所有的对象数据类型存放在堆中。
值得注意的是,对于赋值操作,原始类型的数据直接完整地赋值变量值,对象数据类型的数据则是复制引用地址。
因此会有下面的情况:
let obj = { a: 1 };
let newObj = obj;
newObj.a = 2;
console.log(obj.a);//变成了2
之所以会这样,是因为 obj 和 newObj 是同一份堆空间的地址,改变newObj,等于改变了共同的堆内存,这时候通过 obj 来获取这块内存的值当然会改变。
当然,你可能会问: 为什么不全部用栈来保存呢?
首先,对于系统栈来说,它的功能除了保存变量之外,还有创建并切换函数执行上下文的功能。举个例子:
function f(a) {
console.log(a);
}
function func(a) {
f(a);
}
func(1);
假设用ESP指针来保存当前的执行状态,在系统栈中会产生如下的过程:
调用func, 将 func 函数的上下文压栈,ESP指向栈顶。
执行func,又调用f函数,将 f 函数的上下文压栈,ESP 指针上移。
执行完 f 函数,将ESP 下移,f函数对应的栈顶空间被回收。
执行完 func,ESP 下移,func对应的空间被回收。
图示如下:
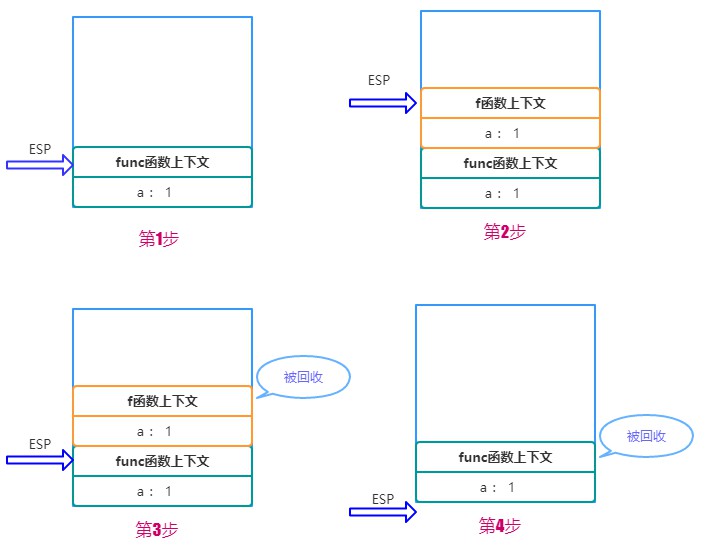
因此你也看到了,如果采用栈来存储相对基本类型更加复杂的对象数据,那么切换上下文的开销将变得巨大!
不过堆内存虽然空间大,能存放大量的数据,但与此同时垃圾内存的回收会带来更大的开销,下一篇就来分析一下堆内存到底是如何进行垃圾回收并进行优化的。
