
001: nodejs中的异步、非阻塞I/O是如何实现的?
在听到 nodejs 相关的特性时,经常会对 异步I/O、非阻塞I/O有所耳闻,听起来好像是差不多的意思,但其实是两码事,下面我们就以原理的角度来剖析一下对 nodejs 来说,这两种技术底层是如何实现的?
什么是I/O?
首先,我想有必要把 I/O 的概念解释一下。I/O 即Input/Output, 输入和输出的意思。在浏览器端,只有一种 I/O,那就是利用 Ajax 发送网络请求,然后读取返回的内容,这属于网络I/O。回到 nodejs 中,其实这种的 I/O 的场景就更加广泛了,主要分为两种:
- 文件 I/O。比如用 fs 模块对文件进行读写操作。
- 网络 I/O。比如 http 模块发起网络请求。
阻塞和非阻塞I/O
阻塞和非阻塞 I/O 其实是针对操作系统内核而言的,而不是 nodejs 本身。阻塞 I/O 的特点就是一定要等到操作系统完成所有操作后才表示调用结束,而非阻塞 I/O 是调用后立马返回,不用等操作系统内核完成操作。
对前者而言,在操作系统进行 I/O 的操作的过程中,我们的应用程序其实是一直处于等待状态的,什么都做不了。那如果换成非阻塞I/O,调用返回后我们的 nodejs 应用程序可以完成其他的事情,而操作系统同时也在进行 I/O。这样就把等待的时间充分利用了起来,提高了执行效率,但是同时又会产生一个问题,nodejs 应用程序怎么知道操作系统已经完成了 I/O 操作呢?
为了让 nodejs 知道操作系统已经做完 I/O 操作,需要重复地去操作系统那里判断一下是否完成,这种重复判断的方式就是轮询。对于轮询而言,有以下这么几种方案:
一直轮询检查I/O状态,直到 I/O 完成。这是最原始的方式,也是性能最低的,会让 CPU 一直耗用在等待上面。其实跟阻塞 I/O 的效果是一样的。
遍历文件描述符(即 文件I/O 时操作系统和 nodejs 之间的文件凭证)的方式来确定 I/O 是否完成,I/O完成则文件描述符的状态改变。但 CPU 轮询消耗还是很大。
epoll模式。即在进入轮询的时候如果I/O未完成CPU就休眠,完成之后唤醒CPU。
总之,CPU要么重复检查I/O,要么重复检查文件描述符,要么休眠,都得不到很好的利用,我们希望的是:
nodejs 应用程序发起 I/O 调用后可以直接去执行别的逻辑,操作系统默默地做完 I/O 之后给 nodejs 发一个完成信号,nodejs 执行回调操作。
这是理想的情况,也是异步 I/O 的效果,那如何实现这样的效果呢?
异步 I/O 的本质
Linux 原生存在这样的一种方式,即(AIO), 但两个致命的缺陷:
- 只有 Linux 下存在,在其他系统中没有异步 I/O 支持。
- 无法利用系统缓存。
nodejs中的异步 I/O 方案
是不是没有办法了呢?在单线程的情况下确实是这样,但是如果把思路放开一点,利用多线程来考虑这个问题,就变得轻松多了。我们可以让一个进程进行计算操作,另外一些进行 I/O 调用,I/O 完成后把信号传给计算的线程,进而执行回调,这不就好了吗?没错,异步 I/O 就是使用这样的线程池来实现的。
只不过在不同的系统下面表现会有所差异,在 Linux 下可以直接使用线程池来完成,在Window系统下则采用 IOCP 这个系统API(其内部还是用线程池完成的)。
有了操作系统的支持,那 nodejs 如何来对接这些操作系统从而实现异步 I/O 呢?
以文件为 I/O 我们以一段代码为例:
let fs = require('fs');
fs.readFile('/test.txt', function (err, data) {
console.log(data);
});
执行流程
执行代码的过程中大概发生了这些事情:
- 首先,fs.readFile调用Node的核心模块fs.js ;
- 接下来,Node的核心模块调用内建模块node_file.cc,创建对应的文件I/O观察者对象(这个对象后面有大用!) ;
- 最后,根据不同平台(Linux或者window),内建模块通过libuv中间层进行系统调用
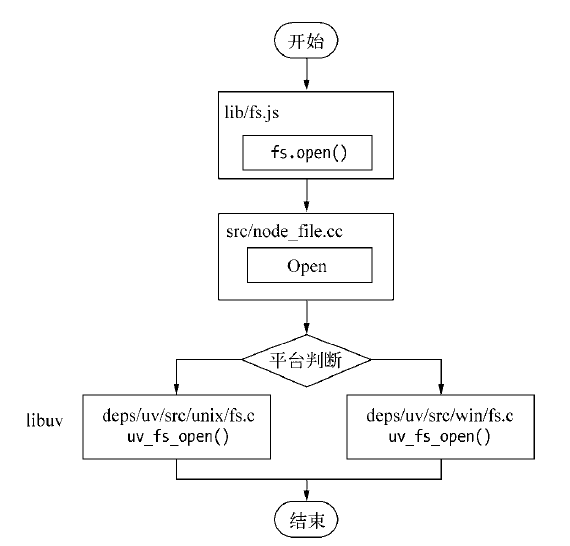
libuv调用过程拆解
重点来了!libuv 中是如何来进行进行系统调用的呢?也就是 uv_fs_open() 中做了些什么?
1. 创建请求对象
以Windows系统为例来说,在这个函数的调用过程中,我们创建了一个文件I/O的请求对象,并往里面注入了回调函数。
req_wrap->object_->Set(oncomplete_sym, callback);
req_wrap 便是这个请求对象,req_wrap 中 object_ 的 oncomplete_sym 属性对应的值便是我们 nodejs 应用程序代码中传入的回调函数。
2. 推入线程池,调用返回
在这个对象包装完成后,QueueUserWorkItem() 方法将这个对象推进线程池中等待执行。
好,至此现在js的调用就直接返回了,我们的 js 应用程序代码可以继续往下执行,当然,当前的 I/O 操作同时也在线程池中将被执行,这不就完成了异步么:)
等等,别高兴太早,回调都还没执行呢!接下来便是执行回调通知的环节。
3. 回调通知
事实上现在线程池中的 I/O 无论是阻塞还是非阻塞都已经无所谓了,因为异步的目的已经达成。重要的是 I/O 完成后会发生什么。
在介绍后续的故事之前,给大家介绍两个重要的方法: GetQueuedCompletionStatus 和 PostQueuedCompletionStatus。
还记得之前讲过的 eventLoop 吗?在每一个Tick当中会调用
GetQueuedCompletionStatus检查线程池中是否有执行完的请求,如果有则表示时机已经成熟,可以执行回调了。PostQueuedCompletionStatus方法则是向 IOCP 提交状态,告诉它当前I/O完成了。
名字比较长,先介绍是为了让大家混个脸熟,至少后面出来不会感到太突兀:)
我们言归正传,把后面的过程串联起来。
当对应线程中的 I/O 完成后,会将获得的结果存储起来,保存到相应的请求对象中,然后调用PostQueuedCompletionStatus()向 IOCP 提交执行完成的状态,并且将线程还给操作系统。一旦 EventLoop 的轮询操作中,调用GetQueuedCompletionStatus检测到了完成的状态,就会把请求对象塞给I/O观察者(之前埋下伏笔,如今终于闪亮登场)。
I/O 观察者现在的行为就是取出请求对象的存储结果,同时也取出它的oncomplete_sym属性,即回调函数(不懂这个属性的回看第1步的操作)。将前者作为函数参数传入后者,并执行后者。
这里,回调函数就成功执行啦!
总结 :
阻塞和非阻塞I/O 其实是针对操作系统内核而言的。阻塞 I/O 的特点就是一定要等到操作系统完成所有操作后才表示调用结束,而非阻塞 I/O 是调用后立马返回,不用等操作系统内核完成操作。- nodejs中的异步 I/O 采用多线程的方式,由
EventLoop、I/O 观察者,请求对象、线程池四大要素相互配合,共同实现。
