006: 对 Content 系列字段了解多少?
对于Content系列字段的介绍分为四个部分: 数据格式、压缩方式、支持语言和字符集。
数据格式
上一节谈到 HTTP 灵活的特性,它支持非常多的数据格式,那么这么多格式的数据一起到达客户端,客户端怎么知道它的格式呢?
当然,最低效的方式是直接猜,有没有更好的方式呢?直接指定可以吗?
答案是肯定的。不过首先需要介绍一个标准——MIME(Multipurpose Internet Mail Extensions, 多用途互联网邮件扩展)。它首先用在电子邮件系统中,让邮件可以发任意类型的数据,这对于 HTTP 来说也是通用的。
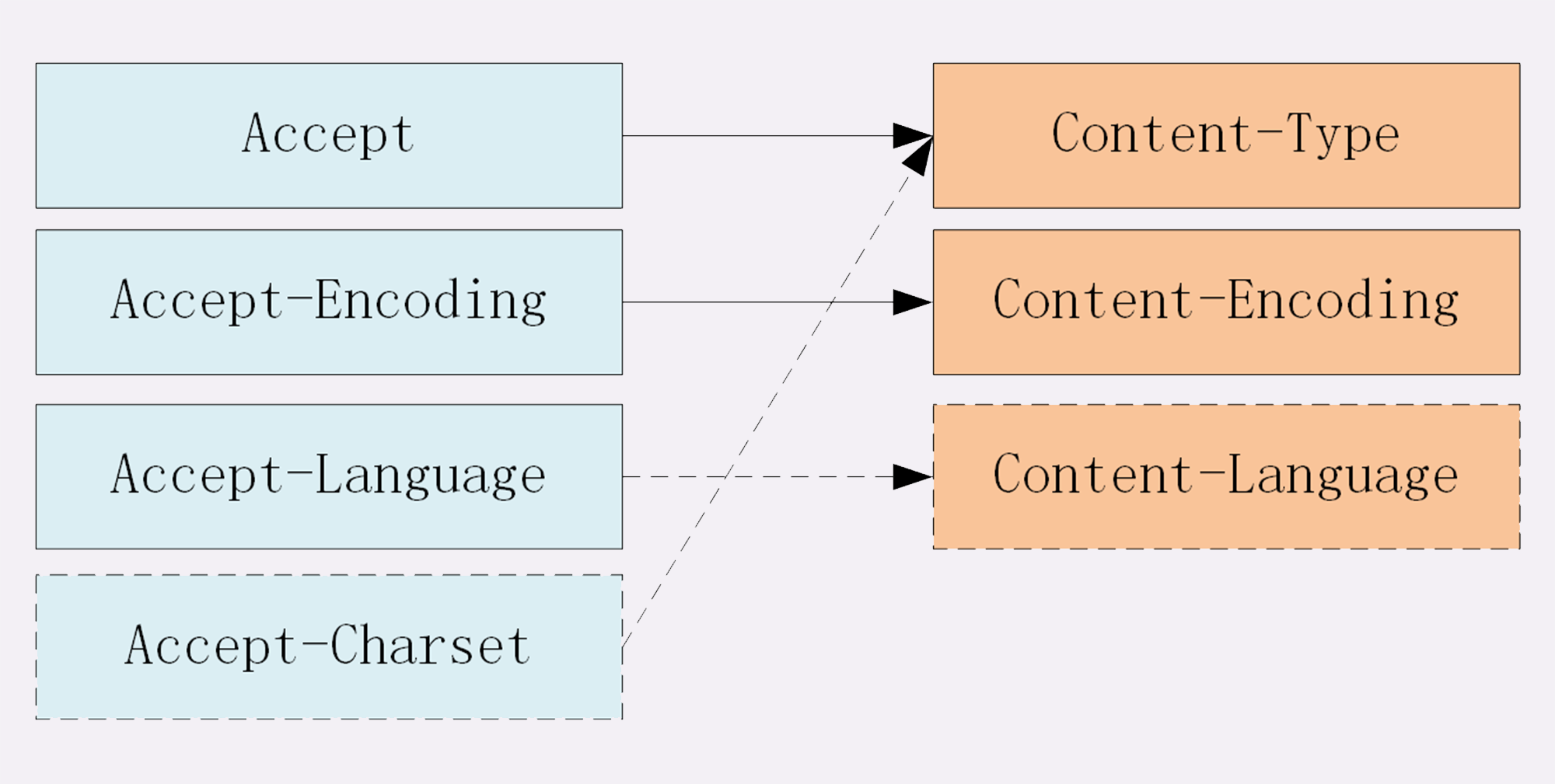
因此,HTTP 从MIME type取了一部分来标记报文 body 部分的数据类型,这些类型体现在Content-Type这个字段,当然这是针对于发送端而言,接收端想要收到特定类型的数据,也可以用Accept字段。
具体而言,这两个字段的取值可以分为下面几类:
- text: text/html, text/plain, text/css 等
- image: image/gif, image/jpeg, image/png 等
- audio/video: audio/mpeg, video/mp4 等
- application: application/json, application/javascript, application/pdf, application/octet-stream
压缩方式
当然一般这些数据都是会进行编码压缩的,采取什么样的压缩方式就体现在了发送方的Content-Encoding字段上, 同样的,接收什么样的压缩方式体现在了接受方的Accept-Encoding字段上。这个字段的取值有下面几种:
- gzip: 当今最流行的压缩格式
- deflate: 另外一种著名的压缩格式
- br: 一种专门为 HTTP 发明的压缩算法
// 发送端
Content-Encoding: gzip
// 接收端
Accept-Encoding: gizp
支持语言
对于发送方而言,还有一个Content-Language字段,在需要实现国际化的方案当中,可以用来指定支持的语言,在接受方对应的字段为Accept-Language。如:
// 发送端
Content-Language: zh-CN, zh, en
// 接收端
Accept-Language: zh-CN, zh, en
字符集
最后是一个比较特殊的字段, 在接收端对应为Accept-Charset,指定可以接受的字符集,而在发送端并没有对应的Content-Charset, 而是直接放在了Content-Type中,以charset属性指定。如:
// 发送端
Content-Type: text/html; charset=utf-8
// 接收端
Accept-Charset: charset=utf-8
最后以一张图来总结一下吧: